CNN-based Single Object Tracking Framework
for
Autonomous Target Tracking Systems
Dong-Hyun Lee
Department of IT Convergence Engineering, Kumoh National Institute of Technology
61 Daehak-ro, 39177
Gumi, Gyeongbuk, South Korea
donglee@kumoh.ac.kr
Abstract
This paper proposes a visual tracking algorithm for videos with convolutional neural network-based single object tracking framework. To consider spatio-temporal constraints of object movement in a video, the proposed network estimates the relative pose change of the next frame with respect to the current frame. For each output of the convolutional layers, a batch normalization layer is added to reduce inertial covariate shift, which is the change in the distribution of network activations. In the training, input images are preprocessed with color distortion and standardization, and the input batches are randomly generated with bidirectional pairs. The proposed algorithm is trained on Visual Object Tracking (VOT) dataset and is tested on the Amsterdam Library of Ordinary Videos for tracking (ALOV300++) dataset, which is a standard tracking benchmark to demonstrate its performance.
Keywords-component; object tracking; artificial intelligence; supervised learning
1. Introduction
A single object tracking task aims to track a target object in a sequence of image frames and estimate the bounding box, which represents the center location, width and height of the target. The single object tracking systems should be able to track a target object among many of the same class or different classes of objects. Moreover, they should be invariant to occlusions, object or background motions, rotations, deformations, and lighting changes.
Numerous research works have done on the convolutional neural network-based approach for image classification such as [1]-[3]. However, they are not applicable for object tracking tasks in a video, which is a challenging problem due to their characteristics such as occlusion, motion blur, illumination change, and size change. Although there have been numerous works on object tracking such as [4] and [5], they are not applicable for tracking unknown object types. The single object tracking focuses on tracking generic objects such that a ground truth bounding box of an arbitrary object is given at the first frame and the tracker should estimate the bounding box of the object at each subsequent frame. The application areas of the generic single object tracking systems are much wider than that of specific object tracking systems since they are not limited to any specific object classes.
There are three main approaches in generic object trackers in terms of learning process. The online learning approaches, such as [6] and [7] train their trackers during test. While these approaches do not require offline training with large amount of data, they are vulnerable to any small shape change of a target object. Moreover, they often require a significant amount of time and computational resources to train the trackers while testing. In the case of the offline learning approaches, such as [8] and [9], a large amount of training data is used to train the trackers in advance of applying them for tracking. The hybrid approaches such as [10] and [11] are considered as the combination of the online and the offline approaches. Although they try to combine benefits from both approaches, they require complex structure and learning process.
The proposed framework in this paper can be categorized as the offline learning approaches. It is based on the Generic Object Tracking Using Regression Networks (GOTURN) from [9], which uses a simple feed-forward network with no online training. Although GOTURN is widely used due to its capability to track novel objects that do not appear in the training set with fast speed, it is vulnerable to the covariate shift and weight initialization. Moreover, it is sensitive to the learning rate and requires a long learning time. To address these disadvantages, the proposed framework utilizes various deep neural network schemes such as batch normalization with no dropout and a sigmoid function as the activation function at the last fully-connected layer. In the training phase, preprocessing schemes such as image standardization and random color distortions are applied. Moreover, a mini-batch of bidirectional image pairs, which consists of forward and backward order of a sequence of image frames is proposed.
2. Proposed Visual Tracking Framework
The overall architecture of the proposed network is shown in Fig. 1. Similar to the most approaches in visual tracking, the proposed network uses the image crop pairs from the previous and the current image frames at each timestep. At the initial frame, the ground truth bounding box of the target object is given to the network and the crop region at the initial frame is defined by padding the width and the height of the ground truth bounding box to two times. For the next frame, the crop region is defined by padding the estimated bounding box from the previous frame to be twice the size. The ConvNet1 and ConvNet2 in the network extract features from a sequence of images and the features are fed into the fully-connected layers.
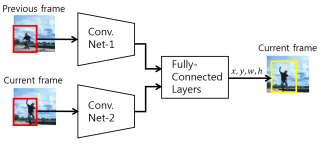
Fig. 1 Visual tracking network architecture.
The architecture of the proposed network is described in Table 1, where Conv and FCL in the table represent the convolutional layer and the fully-connected layer, respectively. The ConvNet-1(2) in Fig. 1 consists of Conv1-1(2), Maxpool1-1(2), Conv2-1(2), Maxpool2-1(2), Conv3-1(2), Conv4-1(2), Conv5-1(2), and Maxpool3-1(2).
Table 1. Network Architecture of the Proposed Tracker
|
Type |
Filters |
Size / Stride |
Output |
|
Conv1-1(2) |
96 |
11 x 11 / 4 |
57 x 57 |
|
Maxpool1-1(2) |
- |
3 x 3 / 2 |
29 x 29 |
|
Conv2-1(2) |
256 |
5 x 5 / 1 |
29 x 29 |
|
Maxpool2-1(2) |
- |
3 x 3 / 2 |
15 x 15 |
|
Conv3-1(2) |
384 |
3 x 3 / 1 |
15 x 15 |
|
Conv4-1(2) |
384 |
3 x 3 / 1 |
15 x 15 |
|
Conv5-1(2) |
256 |
3 x 3 / 1 |
15 x 15 |
|
Maxpool3-1(2) |
- |
3 x 3 / 2 |
8 x 8 |
|
FCL1 |
4096 |
- |
4096 |
|
FCL2 |
4096 |
- |
4096 |
|
FCL3 |
4096 |
- |
4096 |
|
FCL4 |
4096 |
- |
4 |
Although the basic design of the proposed network architecture is based on GOTURN, they have different characteristics. In the proposed network, ConvNet-1 and ConvNet-2 share the same weights, which is not the case in GOTURN. Since the input of the network is a sequence of image frames, the two convolutional networks (ConvNets) must detect similar features from the same target object for longer and robust tracking. By sharing the weights, the two ConvNets generate consistent feature maps for the same object as well as reducing training time. For each output of the convolutional layers, a batch normalization layer and the leaky rectified linear unit (ReLU) function is used as an activation function. The batch normalization reduces internal covariate shift and enables the training process much faster with less careful about initialization [12]. Since the batch normalization acts as a regulator, dropout is not used in the proposed network. For the last fully-connected layer, which is FCL4 in the table, the proposed network uses the sigmoid function is used as an activation function, whereas GOTURN uses a linear function. This causes GOTURN to have high initial loss, to require longer training time, and to be more sensitive to the change of the learning rate.
For robust feature extraction with respect to color distortion, the brightness, contrast, hue and saturation of the training images are randomly distorted. Moreover, the training images pass through the standardization process before fed to the network to have zero mean and unit normal distribution. Note that the image standardization is also used in testing phase. In the training, most of the other approaches use only a forward sequence for training image pair. However, the visual tracker should be able to track an object in video when the video is played backwards. For this reason, the proposed framework generates the random training image pair batch in both forward and the backward sequence for robust training.
The estimated
bounding box in the previous image frame, ![]() , is defined as
, is defined as
![]() ,
(1)
,
(1)
![]()
where ![]() and
and ![]() are the
are the ![]() center position of the
bounding box, which is the offset from the top-left corner of the image frame,
and
center position of the
bounding box, which is the offset from the top-left corner of the image frame,
and ![]() and
and ![]() are the width and the
height of the bounding box, respectively. The width and the height of the image
frame are denoted as
are the width and the
height of the bounding box, respectively. The width and the height of the image
frame are denoted as ![]() and
and![]() , respectively.
, respectively.
The crop box that is used for cropping image patch from the previous
and the current image frame, ![]() , is generated by padding
, is generated by padding ![]() to
two times the width and the height.
It is defined as
to
two times the width and the height.
It is defined as ![]() (2)
(2)
where ![]() ,
, ![]() ,
, ![]() , and
, and ![]() .
.
In the prediction, the output of the proposed
network is defined in the normalized crop image patch of the current image
frame, which is the scaled crop image patch divided by ![]() and
and ![]() for the width and the
height. The network output,
for the width and the
height. The network output, ![]() , is defined as
, is defined as
![]() ,
, ![]() (3)
(3)
where ![]() and
and ![]() are the
are the ![]() center position of the
bounding box, which is the offset from the top-left corner of the normalized
crop image patch, and
center position of the
bounding box, which is the offset from the top-left corner of the normalized
crop image patch, and ![]() and
and ![]() are the width and the
height of the bounding box, respectively. Since the sigmoid function is used as
the activation function of the last fully-connected layer, FCL4, all the
elements in
are the width and the
height of the bounding box, respectively. Since the sigmoid function is used as
the activation function of the last fully-connected layer, FCL4, all the
elements in ![]() range from 0 to 1.
range from 0 to 1.
From (1), (2) and (3),
the estimated bounding box in the current image frame, ![]() , is defined as
, is defined as
![]() , (4)
, (4)
![]()
where
![]() ,
, ![]() ,
,
![]() ,
, ![]() . (5)
. (5)
From (5), the loss in the current image frame is defined as
![]() (6)
(6)
where ![]() is the ground truth
bounding box in the current image frame.
is the ground truth
bounding box in the current image frame.
3. Experiment
The trained networks with the VOT dataset were tested with the ALOV300++ dataset in [13], which consists of 12 different circumstances such as transparency, specularity, clutter, and so on. In the testing, the average intersection of unions (IoUs) and the average failure rates (with the IoU threshold of 0.1) of the proposed network and GOTURN were measured with each of the circumstances as shown in Table 2. The average IoU represents the accuracy of the tracker such that the higher the average IoU, the more accurate target estimation. On the other hand, the average failure rate represents how often the tracker loses track of the target such that the higher the average failure rate, the less successful target tracking. As shown in Table 2, the proposed algorithm outperformed GOTURN for most of the circumstances.
Some of the test results are shown in Fig. 2. As shown in the figure, the estimated bounding boxes from the proposed network (green) are closer to the ground truth (white) than that of GOTURN (red).
Table 2. Test Results of GOTURN and the Proposed Network with ALOV Dataset.
|
Aspects (# of videos) |
GOTURN |
Proposed |
||
|
IoU |
Failure |
IoU |
Failure |
|
|
Light (33) |
0.46 |
0.092 |
0.54 |
0.076 |
|
Surface Cover (15) |
0.48 |
0.052 |
0.50 |
0.038 |
|
Specularity (18) |
0.58 |
0.036 |
0.66 |
0.033 |
|
Transparency (20) |
0.45 |
0.081 |
0.45 |
0.073 |
|
Shape (24) |
0.42 |
0.041 |
0.49 |
0.035 |
|
Motion Smoothness (22) |
0.41 |
0.270 |
0.52 |
0.250 |
|
Motion Coherence (12) |
0.39 |
0.093 |
0.53 |
0.081 |
|
Clutter (15) |
0.43 |
0.150 |
0.52 |
0.130 |
|
Confusion (37) |
0.45 |
0.180 |
0.52 |
0.160 |
|
Low Contrast (23) |
0.46 |
0.140 |
0.56 |
0.099 |
|
Occlusion (34) |
0.47 |
0.110 |
0.51 |
0.100 |
|
Moving Camera (22) |
0.41 |
0.210 |
0.50 |
0.180 |
|
Zooming Camera (29) |
0.45 |
0.083 |
0.50 |
0.067 |
|
Long Duration (10) |
0.45 |
0.071 |
0.54 |
0.070 |


Fig. 2 Selected test results in a sequence of image frames.
4. Conclusion
In this paper, a robust single object tracking framework is proposed. To improve the tracking performance, the proposed network utilized image standardization, batch normalization at each convolutional layer, leaky ReLU as an activation function, sigmoid function at the end of the network. For efficient training, random color distortion is applied to the training image pairs and bidirectional image pair batch were used. The experimental results showed that the proposed network outperforms GOTURN with respect to accuracy and robustness.
Acknowledgment
This research was supported by Kumoh National Institute of Technology.
References
[1] A. Krizhevsky, I. Sutskever, G. E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. pp. 1097-1105, 2012. doi: 10.1145/3065386
[2] J. Dai, Y. Li, K. He, J. Sun, "R-fcn: Object detection via region-based fully convolutional networks," Advances in neural information processing systems, pp. 379-387, 2016. doi: 10.5220/0006511301100120
[3] K. He, X. Zhang, S. Ren, J. Sun, "Deep residual learning for image recognition," IEEE conference on computer vision and pattern recognition, pp. 770-778, 2016. doi: 10.1109/CVPR.2016.90
[4] S. Schulter, P. Vernaza, W. Choi, M. Chandraker, "Deep network flow for multi-object tracking," IEEE Conference on computer vision and pattern recognition, pp. 2730-2739, 2017. doi: 10.1109/CVPR.2017.292
[5] T. Schmidt, R. A. Newcombe, D. Fox, "DART: Dense articulated real-time tracking," Robotics: Science and Systems, 2014. doi: 10.15607/rss.2014.x.030
[6] M. Danelljan, G. Hager, F. Khan, Shahbaz, M. Felsberg, "Discriminative scale space tracking," IEEE transactions on pattern analysis and machine intelligence, vol. 39, pp. 1561-1575, 2016. doi: 10.1109/TPAMI.2016.2609928
[7] S. Hare, S. Golodetz, A. Saffari, V. Vineet, M.-M. Cheng, S. Hicks, L. Stephe, P. Torr, "Struck: Structured output tracking with kernels," IEEE transactions on pattern analysis and machine intelligence, vol. 38, pp. 2096-2109, 2016. doi: 10.1109/ICCV.2011.6126251
[8] J. Kuen, K. M. Lim, C. P. Lee, "Self-taught learning of a deep invariant representation for visual tracking via temporal slowness principle," Pattern recognition, vol. 48, pp. 2964-2982, 2015. doi: 10.1016/j.patcog.2015.02.012
[9] D. Held, S. Thrun, S. Savarese, "Learning to track at 100 fps with deep regression networks," European conference on computer vision, pp. 749-765, 2016. doi: 10.1007/978-3-319-46448-0_45
[10] H. Nam, B. Han, "Learning multi-domain convolutional neural networks for visual tracking," IEEE Conference on Computer Vision and Pattern Recognition, pp.4293-4302, 2016. doi: 10.1109/cvpr.2016.465
[11] Q. Gan, Q. Guo, Z. Zhang, K. Cho, "First step toward model-free, anonymous object tracking with recurrent neural networks," arXiv preprint, 2015. arXiv:1511.06425
[12] S. Ioffe, C. Szegedy, "Batch normalization: Accelerating deep network training by reducing internal covariate shift," International conference on machine learning, pp. 448-456, 2015.
[13] A. W. Smeulders, D. M. Chu, R. Cucchiara, S. Calderara, A. Dehghan, M. Shah, "Visual tracking: An experimental survey," IEEE transactions on pattern analysis and machine intelligence, vol. 36, pp. 1442-1468, 2014. doi: 10.1109/tpami.2013.230